搜索之路
本文主要根据微信公众号 - 码农翻身的两篇搜索文章:《搜索之路》和《搜索之路:Elasticsearch的诞生》整理而来,追寻最原始、最动人的搜索之路
故事的开始
许多年前,一个刚结婚的名叫 Shay Banon 的失业开发者,跟着他的妻子去了伦敦,他的妻子在那里学习厨师。 在寻找一个赚钱的工作的时候,为了给他的妻子做一个食谱搜索引擎,他开始使用 Lucene 的一个早期版本。
倒排索引
倒排索引(英语:Inverted index),也常被称为反向索引、置入档案或反向档案,是一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。它是文档检索系统中最常用的数据结构。
—— 维基百科
例子:
-
文档1的内容:A computer is a device that can execute operations
-
文档2的内容:Early computers are big devices
提取两个文档的单词,并记录这些单词出现在哪个文档中,这就形成了一个简单”粗糙“的倒排索引。

通过这个“倒排索引”,只要给出一个单词,就可以迅速地定位到它在哪个文档中,这种数据结构用来做全文搜索非常合适。
上面的倒排索引有点“粗糙”,还可以在“精化”一下:
对于 a, is, to, that, can, the, are 这些词对搜索来说没什么意义,用户几乎不会用他们搜索,可以过滤掉。
用户搜索的时候输入 computer,但是也希望把 computers 搜出来,所以需要把复数单词,过去式单词等做还原。
用户输入了 device , 但是也希望把 Device 搜出来,所以需要把大写都改成小写。
经过这番转换,文档1和文档2的关键字变成了这样:
文档1:[computer] [device] [execute] [operation]
文档2:[early] [computer] [big] [device]
相应地,倒排索引变成了这样:

当用户想搜索 device 的时候,根据上面整理的倒排索引,就可以快速定位 device 在文档1和文档2中都有出现。
为了更好的统计和高亮显示搜索结果,还可以记录关键词在文章中出现的次数和位置(例如:是第几个单词)

了解”倒排索引“概念和原理后,把可以用来被检索的信息进行提取分析,构建倒排索引,就可以做关键词搜索了。
简单的搜索架构
完整的搜索架构包含两个部分:离线系统和线上系统,离线系统进行数据提取和分析,完成索引的创建。线上系统对外提供查询服务,包括查询理解、查询结果处理等。

| 名词 | 解释 |
|---|---|
| Web文档 | 网页类型数据,例如HTML |
| 文件系统 | 文本类型的数据,例如DOC/CSV/XML等文件 |
| 数据库 | 数据库类型的数据,例如MySQL/MongoDB |
| 人工输入 | 人工按照指定格式输入的数据 |
不论哪种类型数据源,只要可以进行数据提取,然后对数据进行文本分析,就可以创建索引入库。
数据源抽象过程
软件设计就是一个不断抽象的过程,搜索数据源抽象的关键,在于如何把不同的数据源抽象成一个统一的模型。
文件系统、数据库等数据源都可以做成一个 Document 的抽象,Document 可以有很多属性,每个属性都有名称和值, 把属性叫做 Field。比如一个 HTML 文档,可能有 path, title, content 等多个 Field,其中 path 可以唯一地标志这个文档,title 和 content 需要做进行分词,形成倒排索引,让用户搜索。
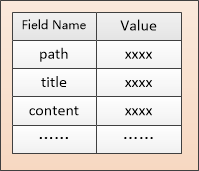
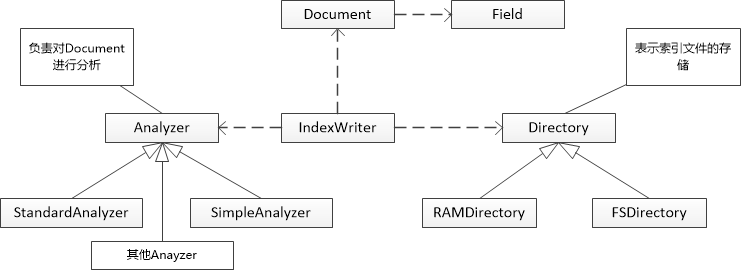
有了 Document 和 Field 以后,分析原始内容划分成一个个 Term。定义一个 Analyzer 的抽象类,当遇到新的数据源时就扩展这个抽象类。针对分析结果入库,这个操作可以 IndexWriter 类来完成,把索引存储在 Directory 中,类图大概就是下面这个样子:
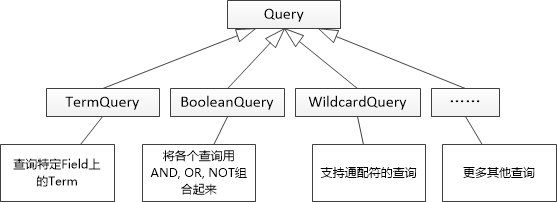
同理,对于用户搜索来说,可以抽象一个叫做 Query 的东西,用来表达用户的搜索要求。当然,这个 Query 也应该允许扩展。
但是这些类使用起来还是比较麻烦, 最好能支持用户输入字符串来表达搜索的意图,例如:(computer or phone) and price,所以需要有个解析器来完成从字符串到 Query 的转化,然后让 IndexSearcher 来接收 Query,就可以实现搜索的功能了

其实上面抽象的过程,就是 Lucene 框架早期的雏形。
故事的发展
直接使用 Lucene 是很难的,因此 Shay 开始做一个抽象层,Java 开发者使用它可以很简单的给他们的程序添加搜索功能。 他发布了他的第一个开源项目 Compass。
后来 Shay 获得了一份工作,主要是高性能,分布式环境下的内存数据网格。这个对于高性能,实时,分布式搜索引擎的需求尤为突出, 他决定重写 Compass,把它变为一个独立的服务并取名 Elasticsearch。
Java API -> Web API
尽管 Lucene 做搜索很强大,但也存在下面两个比较明显的问题:
-
API 用起来太“低级”,需要理解 “Directory”, “Analyzer”, “IndexWriter” 这些概念。(学习成本问题)
-
互联网的数据是海量的,仅仅是单机存储索引是远远不够的。(存储瓶颈问题)
软件开发中遇到的所有问题,都可以通过增加一层抽象而得以解决。
Web开发面对的都是领域模型,比如 User, Product, Blog, Account 之类,用户想做的无非就是搜索产品的描述, 搜索 Blog 的标题,内容等等。可以围绕着领域模型的概念进行搜索的各种操作,这样简单而直接,如同 CRUD,受此启发,可以采用 RESTFul 的方式来描述一个搜索资源。例如:
/website/blog/101 # 表示一个编号为101的博客
/website/user/250 # 表示一个ID为250的用户
‘/website’ 表示一个“索引库”
‘/blog’, ‘/user’ 表示“索引的类型”,可以理解为编程中的领域模型
101, 250 表示数据的ID
上面数据的一般格式是:
/<index>/<type>/<id>
如果和关系数据库做个类比的话:
索引库<—>数据库
索引的类型 <—>数据库的表
定义索引的基本操作:
1、加入文档到索引库
例如:把一个 blog 的“文档”加入索引库,这个文档的数据是 JSON 格式
PUT /website/blog/101
{
"title" : "My first blog entry",
"content" : "Just trying this out...",
"author" : "BenHeart",
...
}
2、从索引库中删除文档
DELETE /website/blog/101
3、在索引库中查询文档
GET /website/blog/101
返回结果:
{
"_index" : "website",
"_type" : "blog",
"_id" : "101",
"_version" : 1,
"found" : true,
"_source" : {
"title": "My first blog entry",
"text": "Just trying this out...",
"author": "BenHeart"
}
}
通过 HTTP + JSON 抽象层,Lucene 那些复杂的 API 就全部被隐藏了。而且,不论什么编程语言,只要可以发起 HTTP 调用,就可以操作索引了。

分布式搜索
简化 API 调用流程后,就需要考虑海量的索引数据如何存储的问题。
直接的思路就是:如果索引太大,就把它切割一下,分成一片一片的,存储到各个机器上

分片以后,保存和搜索索引数据的时候,到哪个机器上去存取呢?
答案:需要保存每个分片 Shard 和机器 Node 之间的对应关系,然后通过余数算法来确定一个 Document 到底保存在哪个 Shard 中
shard1 :node1
shard2 :node2
shard3 :node3
shardNO = Hash(DocumentID) % shardNum
如果我们想增加 shard 数该怎么处理呢?
同数据库分库分表类似,如果是指数级扩容(每次增加 shardNum 的指数倍数),余数算法还是可行的,但是需要做数据迁移处理
例如:
-
扩容前有3个分片:shard0、shard1、shard2
-
扩容后增加为6个分片:shard0、shard1、shard2、shard3、shard4、shard5
-
需要进行数据迁移:shard0 ==> (shard0、shard3)、shard1 ==> (shard1、shard4)、shard2 ==> (shard2、shard5)
缺点:1、必须是指数级扩容,否则余数算法存在问题;2、数据迁移成本高且存在一定风险
另外一种更优的方案:一致性 Hash 算法
针对 shard 数调整的问题,还可以换一种思路:在创建索引库的时候,必须要指定 shard 数量,并且一旦指定,就不能更改
PUT /website
{
"settings" : {
"number_of_shards" : 3
}
}
尽管对用户来说很不友好, 但是也不存在上面的问题了,余数算法的高效和简单确实太有魅力了,而且在某些特定的场景非常适用
分片备份
索引分片后,还存在一个问题:如果其中的某个机器 Node 节点坏掉了,索引的数据就会部分丢失。因此,还要对分片做备份容灾
备份可以用新的 node 来做 replica,也可以为了节省空间, 复用现有的 node 来做 replica。为了做区分,可以把之前的分片叫做主分片 primary shard
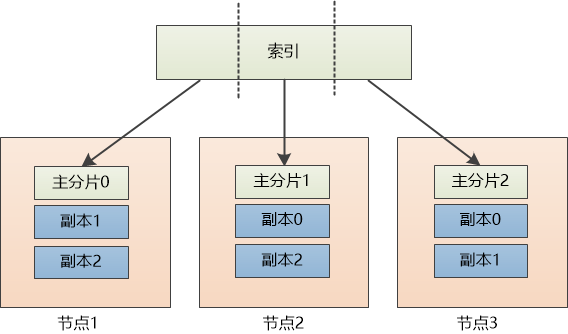
上图中就是复用现有的 node 来做 replica,并且每个主分片有两个副本
PUT /website/_settings
{
"number_of_replicas" : 2
}
现在每个主分片都有两个副本, 如果某个节点挂了也不怕,比如节点1挂了,可以把位于节点3上的副本0提升为主分片0。等到节点1启动后,还可以恢复副本。

索引集群
基于上面的分片设计,可建立一个集群, 这个集群中包含若干 node 节点,既有数据的备份,又能实现高可用性。那么问题又来了,多个 node 节点,如何选择哪一个 node 节点来读写呢?
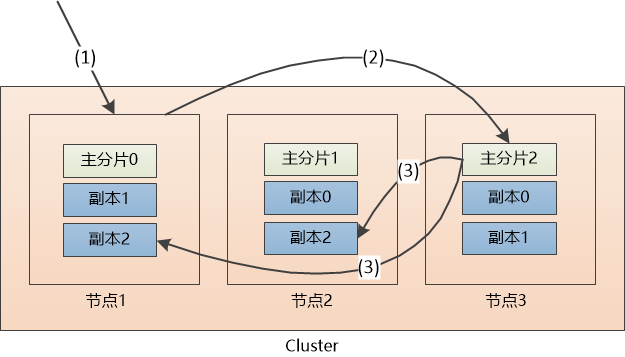
可以让请求发送到集群的任意一个节点,每个节点都具备处理任何请求的能力。写操作具体处理过程如下:
-
(1)假设用户把请求发给了节点1
-
(2)系统通过余数算法得知这个“文档”应该属于主分片2,于是请求被转发到保存该主分片的节点3
-
(3)系统把文档保存在节点3的主分片2中,然后将请求转发至其他两个保存副本的节点。副本保存成功以后,节点3会得到通知,然后通知节点1, 节点1再通知用户。
同样,查询的请求也可以分发到任意一个节点,然后该节点可以找到主分片或者任意一个副本,返回即可。
-
(1) 请求被发给了节点1
-
(2)节点1计算出该数据属于主分片2,这时候,有三个选择,分别是位于节点1的副本2, 节点2的副本2,节点3的主分片2, 假设节点1为了负载均衡,采用轮询的方式,选中了节点2,把请求转发。
-
(3) 节点2把数据返回给节点1, 节点1 最后返回给客户端。

对于一个集群来说,还得有一个主节点(master node),这个主节点在处理数据请求上和其他节点是平等的,但是它还有更重要的工作,需要维护整个集群的状态,增加移除节点,创建/删除索引库,维护主分片和集群的关系等等。
如果这个主节点挂了呢?那只好从剩下的节点中重新选举,这就涉及到分布式系统的各种问题了(一致性)。
推荐一篇大佬的文章:paxos算法记录
故事的结局
第一个公开版本在2010年2月发布,从此以后,Elasticsearch 已经成为了 GitHub 上最活跃的项目之一,拥有33000 + stars,1000 +名 contributors。 一家公司已经开始围绕 Elasticsearch 提供商业服务,并开发新的特性,但是,Elasticsearch 将永远开源并对所有人可用。
据说,Shay 的妻子还在等着她的食谱搜索引擎…
